")
")

 Rob Hudson - Photo by Gino Francesconi
Rob Hudson - Photo by Gino Francesconi
Part I: Process
(Guest blog by Rob Hudson)
My name is Rob Hudson, and I’m the Associate Archivist at Carnegie Hall, where I’ve had the privilege to work since 1997. I’d like to tell you about my experience transforming Carnegie Hall’s historical performance history data into Linked Open Data, and how within the space of about two years I went from someone with a budding interest in linked data, but no clue how to actually create it, to having an actual working prototype.
First, one thing you should know about me: I’m not a developer or computer scientist. (For any developers and/or computer scientists out there reading this right now: skip to the next paragraph, and try to humor me.) I’m a musician who stumbled into the world of archives by chance, armed with subject knowledge and a love of history. I later went back and got my degree in library science, which was an incredibly valuable experience, and which introduced me to the concept of Linked Open Data (LOD), but up until relatively recently, the only lines of programming code I’d ever written was a “Hello, World!” - type script in Basic — in 1983. I mention this in order to give some hope to others out there like me, who discovered LOD, thought “Wow, this is fantastic — how can I do this?”, and were told “learn Python.” Well, I did, and if I can do it, so can you — it’s not that hard. Much harder than learning Python — and, one might argue, more important — is the much more abstract process of understanding your data, and figuring out how to describe it. Once you’ve dealt with that, the transformation via Python is just process — perhaps not a cakewalk, but nonetheless a methodical, straightforward process that you can learn and tackle, step by step.
Now let me tell you a bit about the data that I worked with for my linked data prototype. The Carnegie Hall Archives maintains a database that attempts to track every event, both musical and nonmusical, that has occurred in the public performance spaces of Carnegie Hall since 1891. (Since the CH Archives was not established until 1986, there are some gaps in these records, which we continue to fill in using sources like digitized newspaper listings and reviews, or missing concert programs we buy on eBay.) This database now covers more than 50,000 events of nearly every conceivable musical genre: classical, folk, jazz, pop, rock, world music, and no doubt some I’m overlooking. But Carnegie Hall has always been about much more than music; its stages have also featured dance and spoken word performances, as well as meetings, lectures, civic rallies, political conventions — there was even a children’s circus, complete with baby elephants, in 1934. Our database has corresponding records for more than 90,000 artists, 16,000 composers and over 85,000 musical works. Starting in 2013, we began publishing some of these records to our website, where you can now find the records for nearly 18,000 events between 1891 and 1955. The limited release reflects our ongoing process of data cleanup, and we’re continuing to publish new records each month. For my linked data prototype, I chose to use this published data set, since I knew it was good, clean data.
 Na niedawnej konferencji METRO (Metropolitan New York Library Council) miała miejsce prezentacja przedstawicieli grupy ‘Humanistyka Cyfrowa w New York City' (NYCDH). Grupa ta działa od połowy 2011, i zrzesza zainteresowanych Humanistyką Cyfrową z Nowego Jorku i okolic. Dostarcza ona forum wielu różnym organizacjom i małym grupom osób które pracują nad jakimiś problemami związanymi z humanistyką cyfrową. Uczelnie, w których pracują członkowie komisji sterującej grupy (takie jak NYU, CUNY, Columbia, Pratt i inne) udzielają miejsca na spotkania. Kalendarz grupy jest pełny, często jest kilka wydarzeń lub spotkań w tygodniu. Grupa jest otwarta, i po zarejestrowaniu się każdy członek może wpisać w kalendarz imprezę jaka organizuje i wziąć udział w już ogłoszonej.
Na niedawnej konferencji METRO (Metropolitan New York Library Council) miała miejsce prezentacja przedstawicieli grupy ‘Humanistyka Cyfrowa w New York City' (NYCDH). Grupa ta działa od połowy 2011, i zrzesza zainteresowanych Humanistyką Cyfrową z Nowego Jorku i okolic. Dostarcza ona forum wielu różnym organizacjom i małym grupom osób które pracują nad jakimiś problemami związanymi z humanistyką cyfrową. Uczelnie, w których pracują członkowie komisji sterującej grupy (takie jak NYU, CUNY, Columbia, Pratt i inne) udzielają miejsca na spotkania. Kalendarz grupy jest pełny, często jest kilka wydarzeń lub spotkań w tygodniu. Grupa jest otwarta, i po zarejestrowaniu się każdy członek może wpisać w kalendarz imprezę jaka organizuje i wziąć udział w już ogłoszonej.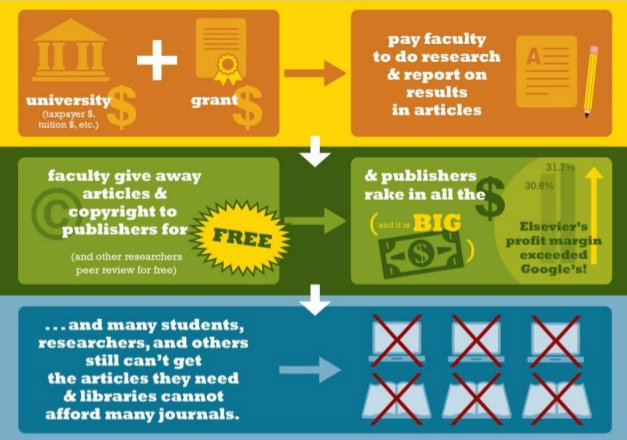

 10 czerwca 2014 r. Sąd Apelacyjny Drugiego Okręgu (południowy Nowy Jork) wydał wyrok, przychylając się do argumentów HathiTrust i odrzucając apel kilku organizacji autorskich, w tym m.in. amerykańskego Authors Guild i szwedzkiego Sveriges Författarförbund. W podsumowaniu wyroku czytamy:
10 czerwca 2014 r. Sąd Apelacyjny Drugiego Okręgu (południowy Nowy Jork) wydał wyrok, przychylając się do argumentów HathiTrust i odrzucając apel kilku organizacji autorskich, w tym m.in. amerykańskego Authors Guild i szwedzkiego Sveriges Författarförbund. W podsumowaniu wyroku czytamy:





