")
")

- Marek Zielinski
Linked Data cz. 2: gdzie są dane?
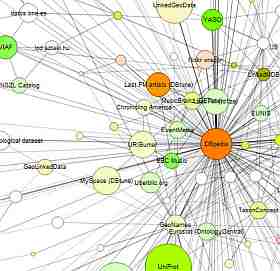 Fragment diagramu Linked Data z portalu LinkedData.org
Fragment diagramu Linked Data z portalu LinkedData.org
Linked Data jest stosunkowo nowym zjawiskiem w sieci WWW, ideą dostępu do danych strukturalnych. Co to są dane strukturalne? WWW jest uniwersalnym nośnikiem informacji czytelnej dla człowieka - wszystkie strony internetowe, artykuły, aplikacje dają nam informacje, które możemy odczytać i zinterpretować, na przykład pytanie: "kiedy przyjedzie następny tramwaj?” i odpowiedź; “za 10 minut". Takie pytanie i odpowiedź nie są jednak łatwe do odczytania przez komputery, które potrzebują informacji w ścisłej strukturze: (“Numer przystanku: 4398, linia tramwajowa: 11, odległość od przystanku: 0.8 km, itp.)
Informacja jest zwykle zapisana w bazach danych, które po wielu latach udoskonalania są bardzo wydajne w przechowywaniu i wyszukiwaniu danych, ale fatalne w wymianie informacji. Każda baza danych zawiera wiele kolumn, nazywanych raczej dowolnie i tylko lokalny system komputerowy umie z niej wyciągnąć dane. Nowy koncept, Linked Data, przybywa tutaj z pomocą. Schemat metadanych Linked Data, o nazwie RDF (Resource Description Framework, struktura opisu zasobów), wymaga, aby dane nie były prezentowane w trudnych do odcyfrowania tabelach, ale w prostych zdaniach, składający się z podmiotu, orzeczenia i dopełnienia. Zamiast wymyślonych nazw kolumn używamy nazw standardowych, a zamiast nazwy podmiotu używamy jego identyfikator URI (Universal Resource Identifier, uniwersalny identyfikator zasobu). Przykładowo, trywialna dla człowieka informacja o tytule tego blogu (przecież możemy przeczytać go powyżej, prawda?) zamienia się w zdanie albo “trójkę” w slangu RDF [1) www.pilsudski.org/portal/pl/nowosci/blog/484, 2) dc:title, 3) "Linked Data cz. 2: gdzie są dane?"]. Pierwsza część to adres URI jednoznacznie wskazujący na ten artykuł, druga to "tytuł” w konkretnym standardzie metadanych (Dublin Core), a trzecia część to tekst tytułu.
Więcej o szczegółach Linked Data i RDF znajdziecie w pierwszym artykule z tej serii,: "Wstęp do Linked Data", i nie będę ich tu powtarzać. W tym blogu chciałbym skupić się na konkretnych źródłach danych dostępnych obecnie na stronach WWW, nad tym jak je znaleźć i co one zawierają. W procesie digitalizacji archiwów często poszukujemy odnośnika do nazw, miejsc, organizacji lub zdarzeń, który byłby stabilny i dostępny. Jeśli pojawia się nazwisko, np. Karol Anders, czy możemy znaleźć źródło, które będzie jednoznacznie wskazywać na rekord tej osoby? Z oczywistych powodów będziemy omawiać tylko te źródła danych, które są publicznie dostępne. Link, który opublikujemy na stronie internetowej, otwartej dla każdego czytelnika, nie może prowadzić do zasobu, który nie jest dostępny dla tego czytelnika. Będziemy analizować nie wszystkie Linked Data, a otwarte Linked Open Data. Ilustracja powyżej pokazuje mały fragment ogromnej sieci Linked Open Data, poniżej kilka wybranych źródeł z wyszczególnieniem tych użytecznych dla archiwisty i bibliotekarza.



 W środę, 15 stycznia 2014 odbyła się w Nowym Jorku doroczna konferencja Metropolitan New York Library Council (METRO). Konferencja, która miała miejsce w nowoczesnym budynku Baruch College (CUNY), zgromadziła ponad dwustu przedstawicieli bibliotek archiwów, uczelni i innych instytucji z Nowego Jorku i okolic. Uczestnicy mieli do wyboru 25 prezentacji i wykładów przedstawiających różne aspekty pracy, możliwości i osiągnięć szeroko rozumianego środowiska bibliotekarskiego. Do przyjętych do prezentacji projektów zakwalifikował się referat przedstawicieli Instytutu Piłsudskiego: Dr Marka Zielińskiego i Dr Iwony Korga p.t.
W środę, 15 stycznia 2014 odbyła się w Nowym Jorku doroczna konferencja Metropolitan New York Library Council (METRO). Konferencja, która miała miejsce w nowoczesnym budynku Baruch College (CUNY), zgromadziła ponad dwustu przedstawicieli bibliotek archiwów, uczelni i innych instytucji z Nowego Jorku i okolic. Uczestnicy mieli do wyboru 25 prezentacji i wykładów przedstawiających różne aspekty pracy, możliwości i osiągnięć szeroko rozumianego środowiska bibliotekarskiego. Do przyjętych do prezentacji projektów zakwalifikował się referat przedstawicieli Instytutu Piłsudskiego: Dr Marka Zielińskiego i Dr Iwony Korga p.t.





