On Wednesday, January 15, 2014 the Annual Conference of the Metropolitan New York Library Council (METRO) was held in New York. The conference, which took place in a modern Vertial Campus at Baruch College (CUNY), brought together more than two hundred representatives of libraries, archives, colleges and other institutions from New York City and surrounding areas. Participants had a choice of 25 presentations and lectures showing various aspects of work, opportunities and achievements of the broadly understood library community. The Pilsudski Institute presented a lecture by Marek Zielinski and Iwona Korg on Digitization of Polish History 1918-1923 describing the digitization project and showing selected archival sources, digitization techniques, special projects and online presentation and statistics.
The conference began with a keynote lecture delivered by a known librarian and blogger Jessamyn West. In the presentation Open, Now! she told us about the possibilities of Open Access with unrestricted, free access to the wide range of sources through the Internet. She talked about Google, Digital Public Library of America, Open LIbrary and legal issues associated with such access.
Next, the participants could choose the lectures from a wide selection of topics. Here are some notes on of those we attended. The program of the conference is available online, the links below lead to the slideshows from the presentations:
Building Authorities with Crowdsourced and Linked Open Data in ProMusicDB (Kimmy Szeto, Baruch College, CUNY and Christy Crowl, ProMusicDB). Linked Data is a great concept, but where to find authoritative data? The authors presented their search for sources of information on music performers and their roles. They found data in many diverse places in the Internet. In the talk they presented the information sources and ways of reconciling the data to obtain a consistent and usable dataset.
Metadata for Oral History: Acting Locally, Thinking Globally (Natalie Milbrodt, Jane Jacobs and Dacia Metes, Queens Library). The representatives of the Queens Public Library presented the latest project on the history of the borough of Queens, including lectures, pictures and memorabilia of the oldest inhabitants of this district. Emphasized was the difficulty of choosing the software and the metadata model, especially in terms of geographical names. Very useful was the pointers on how to describe a personal interview (Who, What, When?, Where, Why?, How?).
Mug Shots, Rap Sheets, & Oral Histories: Building the New Digital Collections at John Jay College of Criminal Justice (Robin Davis, John Jay College of Criminal Justice). The representative of an academic library outlined the stages of work, metadata, and showed some of the most interesting documents from a forthcoming web exhibit on the history of the NYPD (New York Police Department) and recordings of interviews with New York City Mayor Ed Koch.
Wikipedia in Cultural Heritage Institutions (Dorothy Howard, Metropolitan New York Library Council). Dorothy Howard is currently the METRO Wkipedian-in-residence. She presented the latest projects such as Wikipedia GlamWiki, Wikipedia Commons, and told us about the activities of Wikipedians to raise the level and quality of articles, especially regarding medical issues.
Beyond digitization: hacking structured data out of historical documents (Dave Riordan and Paul Beaudoin, NYPL Labs, The New York Public Library). The programmers from the New York Public Library embarked on an ambitious, crowdsourcing project of extracting metadata from vast library collections. They have built tools to entice volunteers to transcribe documents, help them in the task, verify their work by reconciling results of different people, and more, in the process improving and repurposing an Open Source software (Scribe). The topics described in the presentation range from restaurant menus to playbills.
Open Access is a Lot of Work!: How I Took a Journal Open Access and Lived to Tell About It (Emily Drabinski, LIU Brooklyn). A very interesting presentation describing the work with the journal “Radical Teacher” and a change from the traditional paper publishing system to. Open Access, enabled in collaboration with the University of Pittsburg. She stressed that such type of transformation requires a huge amount of work.
The METRO team organized the conference very professionally and took care of every single detail. Thanks and see you next year!
Iwona Korga, January 21, 2014
")
")

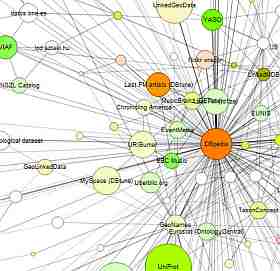 A fragment of a Linked Data Graph from LinkedData.org
A fragment of a Linked Data Graph from LinkedData.org

 Recently (13-18) the Electronic Frontier Foundation (EFF) organized the
Recently (13-18) the Electronic Frontier Foundation (EFF) organized the 






![Based on derivative work: Frédéric GilgameshTablet.jpg: Babylonian [Public domai], via Wikimedia Commons](http://commons.wikimedia.org/wiki/File%3AGilgameshTablet.png){kind=link}